Análisis de Datos de Ventas en la ILC – SELL IN
 |
 |
Introducción
La comprensión del comportamiento del mercado y de los factores que influyen en las ventas es fundamental para garantizar la sostenibilidad y el crecimiento de una organización. El estudio sistemático de la demanda permite optimizar la planeación de producción, mejorar la eficiencia logística y fortalecer la relación con los distribuidores, al tiempo que contribuye a una toma de decisiones más informada y alineada con los objetivos estratégicos. Este proceso implica analizar el desempeño histórico de los productos, identificar patrones de consumo y anticipar variaciones estacionales o coyunturales que puedan impactar los niveles de ventas y los ingresos futuros.
En particular, el mercado de licores ocupa un lugar destacado en la economía regional y nacional, pues integra procesos productivos, dinámicas comerciales y regulaciones fiscales que afectan directamente la competitividad de entidades como la Industria de Licores de Caldas (ILC). Productos como el ron, el aguardiente y otros derivados presentan comportamientos de demanda heterogéneos según la zona geográfica, el tipo de distribuidor y los periodos del año, lo que exige un análisis detallado que considere factores comerciales, tributarios y sociales. Por ello, resulta esencial estudiar las condiciones y variaciones que determinan el desempeño del portafolio, con el fin de fortalecer la gestión comercial y asegurar una planeación más robusta y eficiente.
En este contexto, el uso de herramientas analíticas y tecnologías avanzadas se convierte en un componente clave para comprender y predecir el comportamiento del mercado. El análisis de datos históricos y georreferenciados, junto con técnicas modernas de modelado estadístico y aprendizaje automático, facilita la identificación de patrones espacio-temporales, la evaluación del desempeño por zonas y la estimación de la demanda futura. Plataformas como Python y Microsoft Fabric, así como librerías especializadas para el procesamiento, visualización y modelado, permiten construir modelos de pronóstico más precisos y adaptativos. Estas capacidades fortalecen la toma de decisiones estratégicas, optimizan la planificación comercial y reducen la incertidumbre inherente al mercado, apoyando a la ILC en la mejora continua de su eficiencia operativa y competitividad.
Objetivo
Desarrollar, validar y documentar un modelo de pronóstico de ventas para la ILC que integre las prioridades del negocio con el análisis de los datos históricos, garantizando trazabilidad del proceso, calidad de los resultados y capacidad de replicación y escalabilidad para futuros ciclos de planeación comercial.
Metodología CRISP-DM adaptada al proyecto
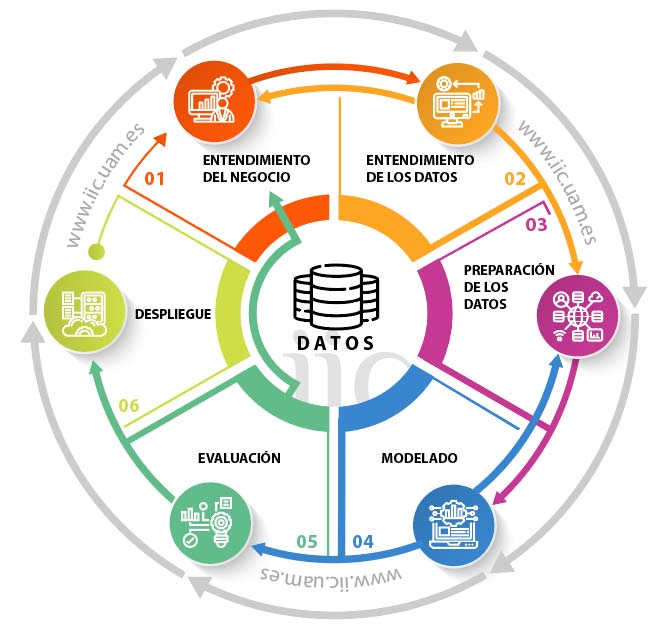
La metodología CRISP-DM (Cross-Industry Standard Process for Data Mining), es ampliamente reconocida como un marco robusto y flexible para proyectos de minería y ciencia de datos. Esta metodología se estructura en seis fases iterativas e interdependientes —entendimiento del negocio, entendimiento de los datos, preparación de los datos, modelado, evaluación e implementación— que permiten avanzar y retroceder de forma no lineal, adaptándose a las necesidades del proyecto y favoreciendo la mejora continua. A continuación se detalla su adaptación para el pronóstico de ventas de licores en la ILC.
1. Comprensión del negocio
Objetivo general: Anticipar la evolución de las ventas —en unidades estandarizadas (UR) y en valor (COP)— por departamento y por producto (ron, aguardiente y derivados), con el fin de fortalecer la planeación comercial, la distribución y la producción.
Necesidades del negocio:
- Identificar patrones de estacionalidad, efectos calendario y variaciones territoriales que influyen en la demanda.
- Comprender cómo cambia el consumo según zona, distribuidor y composición del portafolio.
- Explorar si existen grupos de departamentos con comportamientos similares que permitan desarrollar modelos diferenciados y más precisos.
Estas preguntas guían la formulación del problema analítico y la selección de las técnicas de pronóstico adecuadas.
2. Comprensión de los datos
Origen de los datos: Ventas mensuales sell-in desde 2018, con información asociada a departamento, zona, portafolio y distribuidor.
Exploración inicial:
- Auditoría de calidad: verificación de completitud, revisión de duplicados y consistencia de los datos.
- Análisis descriptivo para identificar tendencias, estacionalidad y variación regional.
Esta fase permite conocer la estructura de los datos, detectar inconsistencias y evaluar su calidad para el modelado.
3. Preparación de los datos
Limpieza y estandarización:
- Conversión de ventas a una unidad común (botellas equivalentes de 750 ml).
- Tratamiento de duplicados, valores faltantes e inconsistencias.
- Agregación al nivel de análisis requerido (departamento × tipo de producto).
- Cálculo de composiciones y participaciones del portafolio.
- Construcción del calendario de referencia (mes, trimestre y año).
El resultado es una base consolidada, depurada y lista para la fase de modelado.
4. Modelado
Estrategia general: Se adopta un enfoque basado en clústeres para capturar la heterogeneidad territorial y los diferentes perfiles de consumo.
Agrupamiento en dos niveles:
- Clustering de departamentos según sus patrones de estacionalidad.
- Subagrupamiento por magnitud de ventas y composición del portafolio.
Selección y ajuste de modelos por clúster/serie:
- Se emplea una combinación de métodos tradicionales y modernos para series temporales, priorizando modelos que equilibren precisión e interpretabilidad.
Validación:
- Backtesting con ventanas rodantes.
- Comparación mediante métricas de desempeño.
- Selección jerárquica (serie → clúster → modelo global), penalizando la complejidad innecesaria.
5. Evaluación
Revisión técnica:
- Análisis del desempeño por horizonte, tipo de producto y región.
- Evaluación de errores (sesgo, varianza y estacionalidad residual).
Criterios de liberación:
- Cumplimiento de umbrales de error por familia de producto.
- Estabilidad del modelo entre ciclos de actualización.
6. Despliegue y monitoreo
Implementación operativa:
- Publicación de resultados en tableros de Power BI con pronósticos, bandas de incertidumbre y comparación frente a metas (en construcción).
- Integración con sistemas fuente (Fabric) y definición del ciclo de actualización (mensual o según necesidad comercial).
Monitoreo continuo:
- Alertas ante degradación de las métricas de desempeño.
- Programación de retraining periódico o condicionado a cambios relevantes del portafolio, la demanda o las reglas de distribución.
Configuración de Python
Código Python
# =============================================================================
# Librerías estándar de Python
# =============================================================================
import sys
import os
import math
import re
import glob
import unicodedata
from datetime import datetime
import warnings
warnings.filterwarnings("ignore")
# =============================================================================
# Procesamiento y manipulación de datos
# =============================================================================
import numpy as np
import pandas as pd
# =============================================================================
# Funciones propias del proyecto
# =============================================================================
import importlib
import funciones_ilc as f
importlib.reload(f)
# =============================================================================
# Visualización
# =============================================================================
import matplotlib.pyplot as plt
import missingno as msno
import ipywidgets as w
from ipywidgets import interact, widgets
from IPython.display import display, clear_output, HTML
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import plotly.io as pio
pio.renderers.default = "vscode"
# =============================================================================
# Modelado y aprendizaje automático
# =============================================================================
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import lightgbm as lgb
from statsmodels.tsa.holtwinters import ExponentialSmoothing
from statsmodels.tools.sm_exceptions import ConvergenceWarningExtracción, Transformación y Carga (ETL)
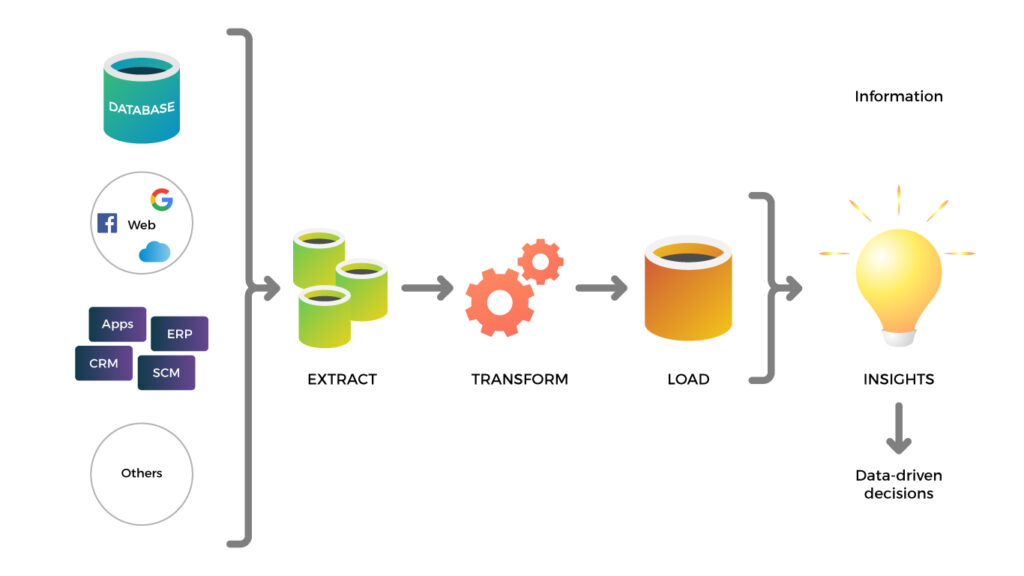
El ETL (Extract, Transform, Load) es el proceso que permite consolidar datos provenientes de múltiples fuentes en un repositorio confiable para análisis. Primero extrae información de sistemas transaccionales, archivos, APIs o bases de datos; luego la transforma limpiando, estandarizando, enriqueciendo y aplicando reglas de negocio para garantizar calidad y consistencia; y finalmente la carga en un destino como un data warehouse o lakehouse. Un buen ETL incorpora validaciones, manejo de errores, control de versiones y metadatos (linaje) para asegurar trazabilidad y reproducibilidad. Al automatizarse y escalar, reduce tiempos operativos, minimiza riesgos por datos inconsistentes y habilita insights oportunos que soportan decisiones basadas en evidencia.
Existen diversas operaciones que se pueden realizar durante la transformación de datos para asegurar su calidad y coherencia. Algunas de las operaciones más comunes son:
- Limpieza de datos: se eliminan los caracteres especiales, espacios en blanco innecesarios, valores nulos o incorrectos.
- Filtrado de datos: se seleccionan los registros que cumplen ciertas condiciones o criterios establecidos.
- Normalización de datos: se ajustan los valores de los datos para que estén dentro de un rango específico o se expresen en una misma unidad.
- Validación de datos: se comprueba la integridad y consistencia de los datos, verificando que cumplan con ciertas reglas o restricciones.
- Transformación de datos: se realizan cálculos o manipulaciones para obtener nuevos valores o derivar información adicional.
Extracción
Código Python
# Importar base de datos
df0 = pd.read_excel('data/Ventas_historico_V2_nov2025.xlsx', sheet_name='Ventas',
usecols="A:AC", engine="openpyxl")
df0.info()RangeIndex: 87850 entries, 0 to 87849 Data columns (total 29 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Concepto 87850 non-null object 1 Zona 86641 non-null object 2 NIT 87850 non-null object 3 Nombre de cliente 87850 non-null object 4 Fecha de factura 87850 non-null object 5 Factura 87850 non-null object 6 Código de producto 87850 non-null object 7 Nombre de producto 87849 non-null object 8 Presentación 87850 non-null int64 9 Unidad 87557 non-null object 10 Cantidad facturada 87850 non-null float64 11 Valor licor 87850 non-null float64 12 Valor Licor COP 87850 non-null float64 13 Cantidad UR 87850 non-null float64 14 Iva cliente 87647 non-null float64 15 IVA ILC 86433 non-null object 16 Especifico cliente 87522 non-null float64 17 Especifico ILC 86433 non-null object 18 Ad Valorem cliente 87499 non-null float64 19 Ad Valorem ILC 86433 non-null object 20 Retención 87700 non-null float64 21 Pedido de venta 87850 non-null object 22 Contrato 86629 non-null object 23 Negocio 87502 non-null object 24 Tipo 87135 non-null object 25 Marca 86951 non-null object 26 Submarca 86926 non-null object 27 Costos de Ventas 87850 non-null object 28 Tipo de Producto 87850 non-null int64 dtypes: float64(8), int64(2), object(19) memory usage: 19.4+ MB
Transformación
Ajuste de Tipo de datos
Se convierte la columna Fecha de factura a formato datetime, manejando errores como valores nulos. Luego se transforman varias columnas numéricas a enteros (Int64) o flotantes (float), asegurando que cualquier valor no válido se convierta en NaN. Finalmente, convierte a tipo categórico (category) aquellas columnas relacionadas con conceptos, zonas, clientes y productos, optimizando memoria y facilitando su uso en análisis posteriores.
Código Python
# Fecha
df0["Fecha de factura"] = pd.to_datetime(df0["Fecha de factura"], errors="coerce")
# Enteros
int_cols = ["Presentación", "Cantidad facturada", "Tipo de Producto"]
for c in int_cols:
if c in df0.columns:
# Convertir a numérico, redondear y luego a Int64 (maneja NaN)
df0[c] = pd.to_numeric(df0[c], errors="coerce").round(0).astype("Int64")
# Flotantes (monetarios/cantidades continuas)
float_cols = [
"Cantidad UR", "Valor licor", "Valor Licor COP", "Iva cliente",
"IVA ILC", "Especifico cliente", "Especifico ILC", "Ad Valorem cliente",
"Ad Valorem ILC", "Retención", "Costos de Ventas"
]
for c in float_cols:
if c in df0.columns:
df0[c] = pd.to_numeric(df0[c], errors="coerce")
# Categóricas
cat_cols = [
"Concepto", "Zona", "NIT", "Nombre de cliente", "Factura", "Código de producto",
"Nombre de producto", "Unidad", "Pedido de venta", "Contrato", "Negocio",
"Tipo", "Marca", "Submarca"
]
for c in cat_cols:
if c in df0.columns:
df0[c] = df0[c].astype("category")Filtros
Se filtra la base de datos para quedarse solo con las facturas que cumplen dos condiciones: que el Concepto esté dentro de una lista específica (COMERCIAL, CONVENIO INTERADMM, FABRI. PT .TERCERO, OTRAS – MARCAS, VENTAS -INTERNACIONA) y que el Tipo de Producto sea igual a 4 (Producto terminado).
Código Python
# Filtrado
concepto_filtro = ["COMERCIAL", "CONVENIO INTERADMM", "FABRI. PT .TERCERO",
"OTRAS - MARCAS", "VENTAS -INTERNACIONA"]
tipo_producto_filtro = 4
df_filter = df0[(df0["Concepto"].isin(concepto_filtro)) &
(df0["Tipo de Producto"] == tipo_producto_filtro)
]
print(f"Base original: {df0.shape[0]} filas")
print(f"Base filtrada: {df_filter.shape[0]} filas")Base original: 87850 filas Base filtrada: 50126 filas
Faltantes
Identificar y cuantificar los valores faltantes que tiene cada columna del DataFrame filtrado.
Código Python
# Verificación de datos faltantes
def contar_faltantes_por_columna(df: pd.DataFrame) -> pd.Series:
"""
Retorna un Series con la cantidad de valores faltantes (NaN) por columna.
"""
return df.isna().sum()
faltantes = contar_faltantes_por_columna(df_filter)
# Mostrar solo las columnas que tienen al menos un valor faltante
faltantes_con_datos = faltantes[faltantes > 0].sort_values(ascending=False)
print(faltantes_con_datos)IVA ILC 1379 Ad Valorem ILC 1379 Especifico ILC 1379 Costos de Ventas 677 Ad Valorem cliente 204 Especifico cliente 181 Iva cliente 57 Retención 29 Negocio 1 dtype: int64
Consistencia de los datos
Revisar y ordenar las presentaciones disponibles en la base de datos, con el fin de identificar valores fuera del rango esperado —mínimo 50 ml y máximo 2000 ml—. En caso de encontrar presentaciones diferentes, como 29 ml, estas deben verificarse y corregirse para garantizar la consistencia y validez de los datos antes de continuar con el análisis.
Código Python
# Mostrar presentaciones
presentaciones = df_filter["Presentación"].dropna().unique().tolist()
presentaciones = sorted(presentaciones)
print("Presentaciones (ml):", presentaciones)
# Seleccionar columnas
pd.set_option("display.max_colwidth", None)
columnas_interes = ["Nombre de producto", "Presentación"]
# Filtrar Presentación de 29 ml
print("\nPresentaciones con 29 ml:")
display(df_filter.loc[df_filter["Presentación"] == 29, columnas_interes])
# Reemplazar valores
df_filter.loc[df_filter["Presentación"] == 29, "Presentación"] = 1750Presentaciones (ml): [29, 50, 250, 295, 375, 700, 750, 1000, 1500, 1750, 2000] Presentaciones con 29 ml:
| Nombre de producto | Presentación | |
|---|---|---|
| 82633 | AGUARDIENTE DEL PUTUMAYO SIN AZÚCAR 1750 VIDRIO 29° NP | 29 |
| 86214 | AGUARDIENTE DEL PUTUMAYO SIN AZÚCAR 1750 VIDRIO 29° NP | 29 |
| 87398 | AGUARDIENTE DEL PUTUMAYO SIN AZÚCAR 1750 VIDRIO 29° NP | 29 |
Reclasificación de datos
Reclasificar permite alinear la información con las reglas de negocio y la estructura real de la operación comercial. Corregir estas inconsistencias evita que registros equivalentes queden dispersos en categorías distintas, mejora la coherencia de los análisis posteriores y reduce el riesgo de sesgos en indicadores de ventas.
Código Python
# Zonas de interés
zonas_objetivo = ["CHOCO-PLA", "CAQUETA-EX", "NAR- AGTE", "DEG-CALDAS"]
# Filtrar filas de zonas y ver en qué Concepto están
df_zonas = df_filter.loc[df_filter["Zona"].isin(zonas_objetivo), ["Zona", "Concepto"]]
# Ver combinaciones únicas Zona–Concepto
df_zonas_unique = df_zonas.drop_duplicates()
display(df_zonas_unique)
# Mapeo de Zona -> Concepto destino
reclasifica = {
'CHOCO-PLA' : 'OTRAS - MARCAS',
'CAQUETA-EX': 'OTRAS - MARCAS',
'NAR- AGTE' : 'CONVENIO INTERADMM',
'DEG-CALDAS' : 'DEG CON IMPUESTOS'
}
# Aplicar reclasificación
mask = df_filter['Zona'].isin(reclasifica.keys())
df_filter.loc[mask, 'Concepto'] = df_filter.loc[mask, 'Zona'].map(reclasifica)| Zona | Concepto | |
|---|---|---|
| 0 | CHOCO-PLA | OTRAS – MARCAS |
| 2 | CHOCO-PLA | COMERCIAL |
| 40 | CAQUETA-EX | COMERCIAL |
| 41 | CAQUETA-EX | OTRAS – MARCAS |
| 112 | NAR- AGTE | COMERCIAL |
| 113 | NAR- AGTE | CONVENIO INTERADMM |
| 265 | DEG-CALDAS | COMERCIAL |
Crear características
La creación de nuevas características a partir de variables existentes es una etapa clave en la preparación de datos, pues permite enriquecer la información utilizada en los análisis y modelos. En este caso, a partir de la columna Fecha de factura se generan las variables Mes y Año, que facilitan el estudio de patrones temporales como estacionalidad, tendencias y variaciones interanuales. Estas nuevas características no solo simplifican la segmentación temporal de las ventas, sino que también permiten agrupar, comparar y modelar el comportamiento comercial con mayor precisión, mejorando la interpretación y la capacidad predictiva de los modelos posteriores.
Código Python
# Crear columnas Mes y Año a partir de la fecha
df_filter = df_filter.copy()
df_filter["Mes"] = df_filter["Fecha de factura"].dt.month
df_filter["Año"] = df_filter["Fecha de factura"].dt.yearCarga
La etapa de Carga (Load) es la fase final de un proceso ETL (Extracción, Transformación y Carga) y consiste en almacenar los datos que ya fueron depurados, transformados y estructurados en un destino definitivo. Este destino puede ser un archivo (CSV, Parquet, Excel), una base de datos transaccional, un almacén analítico (Data Warehouse), un Data Lake o cualquier sistema donde la información vaya a ser consumida por aplicaciones, analistas o modelos. Su propósito es garantizar que los datos estén disponibles, organizados y accesibles para procesos posteriores de análisis, visualización o modelado.
Código Python
# Exportar a CSV
df_clean = df_filter.copy()
df_clean.to_csv('data/df_clean.csv', index=False, encoding='utf-8-sig')Análisis Exploratorio de Datos (EDA)
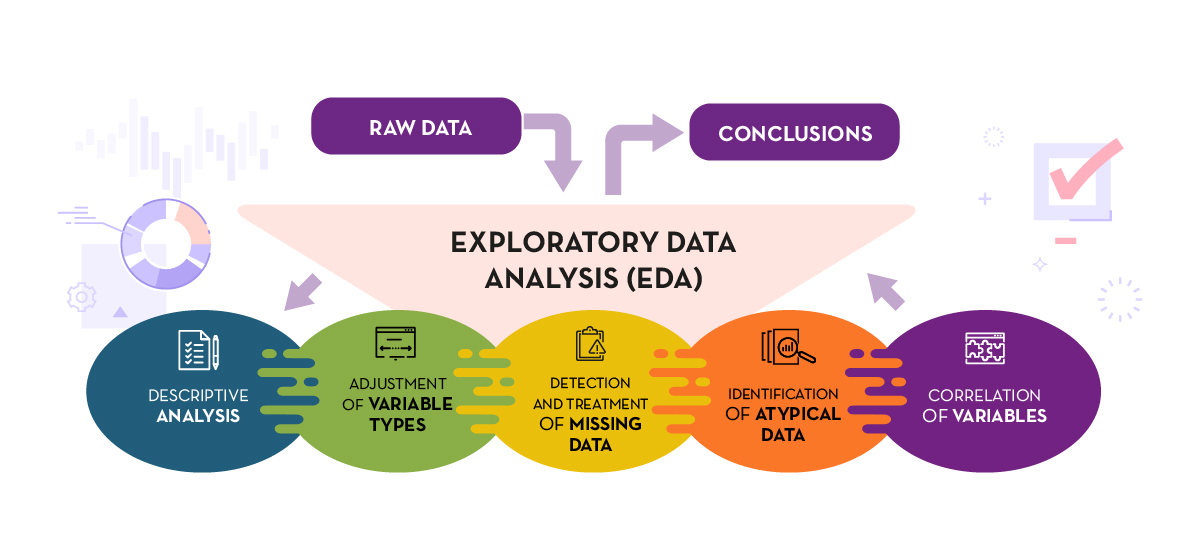
El EDA (Exploratory Data Analysis) es la fase en la que se entiende el conjunto de datos antes de modelar: se describen distribuciones y medidas resumen, se validan y ajustan tipos de variables, se detectan y tratan valores faltantes y atípicos, y se exploran relaciones entre variables mediante tablas, gráficos y métricas de dependencia. Este proceso revela sesgos, errores de captura y patrones temporales o espaciales, ayuda a formular hipótesis, elegir transformaciones y seleccionar características relevantes. Un buen EDA deja datos consistentes, documenta supuestos y criterios de limpieza, y orienta decisiones posteriores (modelos, segmentaciones o pruebas estadísticas) con evidencia y contexto.
La siguiente gráfica muestra la serie temporal mensual de ventas agregadas (suma) en Cantidad UR —expresada en botellas equivalentes de 750 ml— para el periodo enero 2018 hasta noviembre 2025. Se observa un comportamiento estacional, con picos recurrentes en algunos meses del año y caídas pronunciadas en otros, lo que evidencia una alta variabilidad mensual. A lo largo del horizonte analizado se aprecia además un crecimiento en los niveles máximos, ya que los picos más recientes alcanzan valores superiores a los de los primeros años, destacándose un repunte fuerte hacia el final del periodo (con máximos por arriba de las 7 millones de botellas 750 ml). En conjunto, la serie combina tendencia creciente, estacionalidad y fluctuaciones mensuales que sugieren la influencia de ciclos comerciales y eventos específicos de mitad y fin de año.
Código Python
# Serie temporal agregada
df_sum_m, fig = f.time_series_line(df_clean,
period="mensual", #'mensual','anual'
stat="suma", # 'sum','mean','median','min','max','sd'
date_col="Fecha de factura",
value_col="Cantidad UR",
y_label="Cantidad UR (botellas 750 ml)",
y_max=8000000,
width=1000, height=550)